📢 設計・開発・技術情報に関わる読者の皆さまへ
連載では「トリセツ(取扱説明書)」を題材に解説していますが、本書で扱う「iiRDS」および情報設計の対象は、紙の冊子マニュアルだけに留まりません。
国際規格(IEC/IEEE 82079-1)が定義する通り、対象は 「製品の利用に関わるすべての情報(Information for Use)」 です。設計書、仕様書、開発ドキュメント、FAQ、サービスマニュアルなど、製品のライフサイクルに関わるあらゆる技術情報に適用できます。
「社内の膨大な開発ドキュメントをAIに正しく読み込ませたい」「技術資産のハルシネーションを構造で防ぎたい」という設計・開発部門の皆さまにとっても、全く同じ思想と技術が適用可能です。ぜひ「自社の技術文書」に置き換えて読み進めてみてください。
1.AI誤読のメカニズムとその解決策を探るステップ
「マニュアルのPDFをAIに放り込めば、あとはAIが勝手に読んで答えてくれる」 生成AIの進化により、現場ではそんな期待が高まっています。実際、Googleの「NotebookLM」のようなUIを備えたツールが登場し、PDFをドラッグ&ドロップするだけで、誰もが簡単にRAG(検索拡張生成)を体験できる時代になりました。
NotebookLMの最大の魅力は、回答の末尾に「参照元(ソース)」の番号が付き、AIがどこを読んで答えたかを指差し確認できることです。 「これでもう、AIの嘘(ハルシネーション)に騙されることはない!」と期待されます。……でも、本当にそうでしょうか?
技術文書のプロとしては、ここで一つの厳しい疑問を持ったほうが良いのかも知れません。 「複数の類似製品(旧型と新型など)が混ざったPDFを読ませたとき、AIは本当に『正しい機種』の情報を混同せずに抜き出せるのか?
結論から言えば、そのままのPDFでは、AIは情報を混ぜ合わせ、もっともらしく、間違った内容を提示してしまいます。今回は、NotebookLMを使った実証実験をとおして、AIに「文脈を推測させる」ことのリスクと、それを未然に防ぐため、メタデータの国際規格 IEC PAS 63485(iiRDS) による構造化の絶対的な有用性を明らかにします。
【補足情報】
▼検証資料について 本記事の検証に使用した生成AIで読み込んだ入力資料など、資料編ページに掲載しております。ご自身で実際に試される際にご活用ください。(資料編ページはこちらへ)
▼使用した生成AIについて 検証にはGoogle NotebookLMを使用しています。
NotebookLMは、Googleアカウントがあれば誰でも無料で利用できます。基本的な使い方やその他の機能については、Googleの公式ヘルプ等をご参照ください。
https://notebooklm.google.com/
AI誤読のメカニズムとその解決策を探るステップ
本記事では、この「AIの誤読」のメカニズムと、それを防ぐための解決策を紐解くために、以下のステップで検証を進めます。
ステップ1:非構造化データの限界を知る(実験1)
まずは、BtoBマニュアルの現場で日常的に書かれがちな「人間の暗黙知」を含んだテキスト(非構造化データ)をNotebookLMに読み込ませます。人間なら文脈で判断できる記述が、AIをどのように混乱させ、情報の混同(コンタミネーション)を引き起こすのかを観察します。
ステップ2:iiRDSによる構造化の威力を検証する(実験2)
次に、全く同じテキスト情報に対し、国際標準規格であるIEC PAS 63485 (iiRDS) に基づくメタデータを付与した「構造化データ」を用意します。AIがこのメタデータを道しるべとすることで、関係のない情報をシャットアウトし、完璧な回答を導き出すプロセスを確認します。
ステップ3:AI時代のドキュメント設計を考察する
最後にこれらの結果を踏まえ、なぜAIに「毎回推論させる」ことがリスクとなるのか、そしてRAGを安全に運用するために不可欠な「データのガードレール」の重要性について考察します。
それでは、さっそく最初の実験を見ていきましょう。
2.実験1:暗黙知を含む「非構造化データ」はどう読まれるか?
2.1 実験準備
NotebookLMがどれほど手軽でも、読み込ませる元のデータ(PDF)の書き方によって、結果は大きく変わります。今回は、BtoBマニュアルの現場で意図せずに発生させてしまうかもしれない 「類似機能の説明や、操作時の場合分けが、本文内で明確に記述されなかったケース」 で検証してみます。
【前提の共有:架空の製品「SP-Xシリーズ」】
実験の題材として、架空の産業用フィルター「SP-Xシリーズ」のマニュアルを想定します。事前に、前提知識として製品仕様を共有します。
- 標準モデル(SP-X100): フィルター処理に「ヒーター方式」を採用(リスク:高温やけど)
- 海外モデル(SP-X200): フィルター処理に「特殊溶剤」を採用(リスク:化学熱傷)
開発者やベテラン作業者であれば、この仕様の違い(暗黙知)は当然のように頭に入っています。
【実験用のテキスト】
では、その暗黙知を持った人間が書いた、以下のマニュアル本文(非構造化データ)を見てみます。
■安全上のご注意
本機はフィルター加熱用にヒーターを使用するため、運転直後は高温になります。絶対に素手で触れないでください。 また、特殊溶剤を使用するため、液漏れ時に皮膚に触れると炎症を起こす化学熱傷(ケミカルバーン)のリスクがあります。耐薬品手袋を着用してください。
■電源仕様
標準モデル(SP-X100)はAC100Vに対応しています。海外モデル(SP-X200)は仕様が異なりますのでご注意ください。AC200Vの専用コンセントが必要です。
資料1:非構造化マニュアル
【人間とAIの「読み方」の違い】
前提知識を持つ人間がこれを読めば、「前半のヒーターの警告はSP-X100の話で、後半の溶剤の警告はSP-X200の話だな」と、脳内で自動的に場合分けをして正しく読み解くことができます。 マニュアル制作の現場でも、「前後の文脈から読めばわかるはず」「同じことを何度も書くとくどい」という理由から、主語の省略や、暗黙の紐付けは、意図せずにやってしまっているかもしれません。
しかし、テキストデータとして客観的に見ると、「安全上のご注意」の段落には 「どの機種のリスクなのか」という主語が明確に記述されていません。
【今回の検証テーマ】
このような「人間なら文脈で補完できるが、データとしては条件が明記されていないテキスト」をNotebookLMに読み込ませた場合、RAG(検索AI)はどう動くでしょうか? AIが正しく機種とリスクを紐付けられるのか、それとも混乱してしまうのか。実際に検証してみます。
2.2 実験結果:情報の混同(コンタミネーション)の発生
先ほどのテキストをNotebookLMにアップロードし、以下の質問を投げてみます。
【ユーザーの質問】
【AI(NotebookLM)の回答】
【NotebookLM画面イメージ】
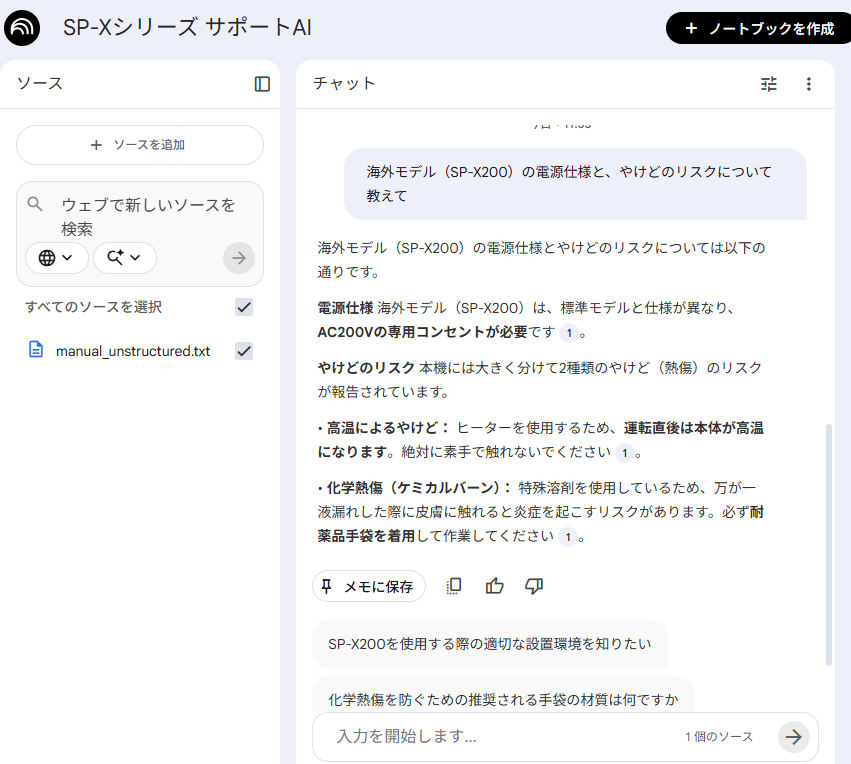
【AIの回答と結果の分析】
仮説通り、AIは情報を混同しました。 電源仕様(AC200V)については正解していますが、やけどのリスクについて「高温によるやけど(ヒーター)」と「化学熱傷(溶剤)」の両方を、SP-X200のリスクとして列挙しています。
これは、AIが、ソースに登録された情報を参考にして、「やけど・炎症」に関連する箇所をすべて拾い上げ、そのまま結合してしまった結果です。
このように、人間にとっては「読めばわかる(暗黙の了解)」テキストであっても、AIにとっては「文脈の境界がないフラットなデータ」にすぎません。そのままRAG(検索システム)に放り込むと、今回のように異なる機種の仕様や警告が混ざり合う 「情報の混同(コンタミネーション)」 という重大な事故を引き起こします。
では、AIに「ここはSP-X100だけの話」「ここはSP-X200の話」と明確に区別させ、確実な回答を引き出すにはどうすればよいのでしょうか? ここで、前々月号・前月号でお伝えしてきた 「メタデータ(iiRDS)」の出番です。
3.実験2:「構造化データ」の投入
3.1 実験準備
非構造化データが引き起こす間違いの可能性を確認したところで、今度は 「AIが迷わないように整理されたデータ」 で確認します。
書かれているマニュアルの情報(文字)自体は先ほどと同じです。しかし、今回はテキストをトピックごとに区切り、それぞれの冒頭に「これはどの機種の、何に関する情報か」を示すメタデータ(タグ) を付与しました。ここでは、国際標準規格であるIEC PAS 63485(iiRDS) の語彙を用いて、Markdown形式で構造化しています。
【構造化データのイメージ(Markdown形式)】
# Identity: Topic-002
# ProductVariant: SP-X200
# InformationType: SafetyWarning
**【化学熱傷注意】**
本機は特殊溶剤を使用するため、液漏れ時に皮膚に触れると炎症を起こす化学熱傷(ケミカルバーン)のリスクがあります。耐薬品手袋を着用してください。資料2:構造化マニュアル
3.2 実験結果:ノイズ情報が完全に除外された
NotebookLMのソースをこの「構造化データ」に切り替え、先ほどと全く同じ質問を投げてみます。
【ユーザーの質問】
【AI(NotebookLM)の回答】
【NotebookLM画面イメージ】
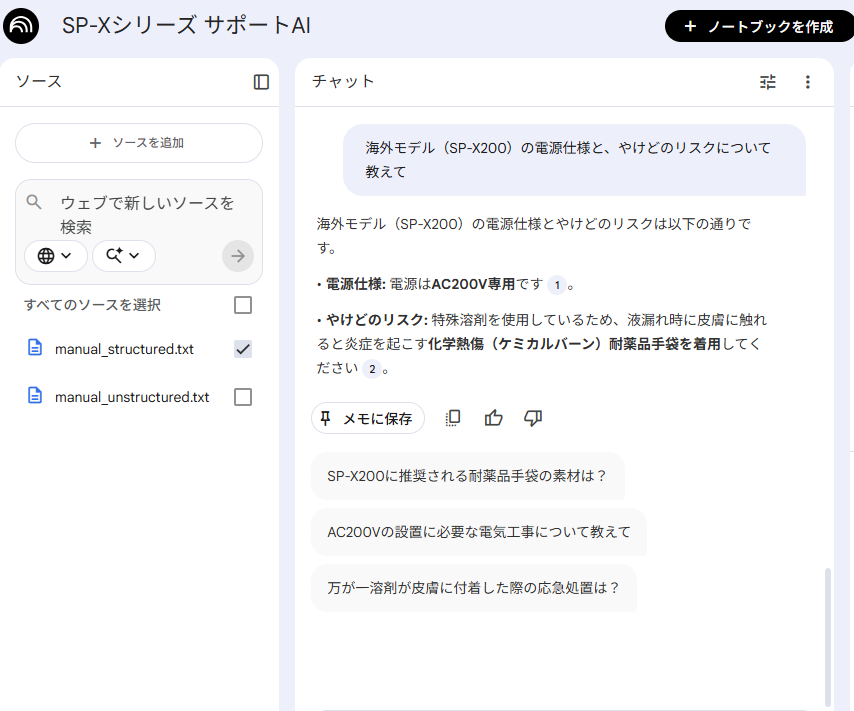
先ほど混入していた「標準モデルの高温やけど(ヒーター)」というノイズ情報が完全に除外されました。
4.考察:なぜAIは間違え、どうすれば防げるのか?
なぜ、実験2では情報の混同が起きなかったのでしょうか? それは、AIに「文脈を推測させる(おそらくこの辺りだろう)」という余地を与えず、メタデータによって「ここがSP-X200の警告だ」と確定させたためです。質問の中に「SP-X200」というキーワードが含まれていたため、AIは「# ProductVariant: SP-X200」というタグが付いた情報のブロック(チャンク)だけをピンポイントで読みに行きました。
この実験結果から、RAG構築における3つの重要なポイントが見えてきます。
① 単なる「チャンク化」では解決しない
近年、社内文書を読み込ませ、企業レベルで文書情報を活用する「エンタープライズRAG」の導入が進んでいますが、非構造化データをそのままロードすれば情報の混同が起こります。これを防ぐために「段落ごとに細かく分割(チャンク化)すればいい」と考えられがちですが、それだけでは不十分です。 分割した1つのチャンク内に場合分けが混在していればAIは迷います。単に切り刻むのではなく、「何の情報を記述しているのか」をあらかじめ割り当てるメタデータの付与が重要になります。
② 毎回「推論」させることのリスクと非効率
マニュアルに記載されている仕様や警告は、誰がいつ読んでも変わらない「確定情報」です。それにもかかわらず、質問が発生するたびに毎回AIにゼロから推論させるのは、実験1のような誤答リスクを生むだけでなく、計算コスト(時間・電力)の面でも非常に非効率です。AIの回答プロセスを「確率的な推論」から「確定検索」へと変える必要があります。
③ エンタープライズRAGにおける「ガードレール」の必要性
エンタープライズRAGの業務利用において、最も恐れるべきはAIの「暴走(もっともらしい嘘の生成)」です。非構造化データの海を自由に泳がせると、AIは悪意なく情報をブレンドしてしまいます。 メタデータは、AIに対して「ここから先は読んではいけない」「この条件に合致するものだけを出力せよ」と制限をかける強固なガードレールとして機能します。推論の自由度をあえて奪うことが、安全性を担保するのです。
5.まとめ:AI時代の「情報提供者が果たすべき役割」
AIという強力なエージェントがユーザーに代わってマニュアルを読み解き、回答を提示する時代。それは劇的な利便性をもたらす一方で、AIの読み間違い(ハルシネーション)が、誤った情報や生命に関わる「危険な回答」をユーザーに届けてしまうリスクと隣り合わせの時代でもあります。
AIを介した情報取得が前提となるならば、情報を発信する企業側には、「AIが迷うことなく、正確かつ安全に情報を抽出できる状態」 でデータを提供する必要が生じます。それこそが、情報提供者が果たすべき新しい、そして最も重要な役割ではないでしょうか。
この役割を果たすための具体的な手段が、情報の「塊(チャンク)」に対して、その意味や属性を定義するメタデータを付与することです。さらに、このメタデータは自社独自のルールに留めるのではなく、国際標準規格であるIEC PAS 63485(iiRDS) に準拠させることが極めて重要です。
標準化されたメタデータは、単に情報を分類するための「タグ」ではありません。AIが関係のない情報を混同することを防ぎ、必要な情報だけを抽出させるための 「強力なガードレール」 として機能します。このガードレールをいかに精密に設計し、情報の安全性を担保していくか。それこそが、これからのテクニカルコミュニケーションにおける最重要課題であり、情報設計者が挑むべき新たなフロンティアなのです。
6.次回予告:構造化は「誰」がやるのか? 〜Human-in-the-Loopの限界〜
今回は、「メタデータがないとAIは情報を混同し、メタデータがあれば完璧に動く」という事実を実証しました。しかし、現場の皆様からはこんな悲鳴が聞こえてきそうです。
「理屈は分かった。でも、何百ページもある既存のPDFに、誰がメタデータをつけるのか?」
「AIにタグ付けの下書きをさせて、人間が最後にチェックすればいい(Human-in-the-Loop)」と考える方もいるかもしれません。しかし、数千・数万件に及ぶチャンクとタグの整合性を、人間が全件目視でチェックし続けるのは現実的ではありません。 人間のチェック作業そのものがボトルネックになってしまう、「Human-in-the-Loopの限界」がすぐに訪れます。
人間がボトルネックにならないためには、PDFの解析からチャンク化、iiRDSメタデータの付与、そしてタグの矛盾検証までを、「AI同士を組み合わせて自動化・省力化する」 パイプラインが必要です。
次号(4月号)では、この「既存PDFの自動構造化ワークフロー」と、その検証結果を公開します。 AIを安全に使うためのデータは、AI自身に作らせる。次世代のドキュメント資産化の具体策に、どうぞご期待ください。
<終わりー AI時代の情報設計:マニュアルの「暗黙知」が引き起こすAIの誤読>







