<この記事のポイント>
私たちが情熱を注いで作った「正確なトリセツ(User Manual)」。しかし、ユーザーが現場でそれを「見つける(Discovery)」ことができなければ、その価値は世界に届いたことにはなりません。連載初回に投げかけた「AIは価値を正しく届けられるか?」という問いへの答えがここにあります。AIと構造化データを使って「検索で見つからない」壁を突破する、情報のラストワンマイル実験レポートです。
はじめに
本連載の第1回では、最終回のテーマとして 「AIは、トリセツ(User Manual)の価値を『正しく』世界に届けられるか?」 という問いを投げかけました。
今回向き合うのは、まさにその「届ける」という最後の難関です。どんなに良い情報を作っても、ユーザーの手元に届かなければ意味がない。この「ラストワンマイル」の問題を解決するために、今回はAIと構造化データを組み合わせた、新しい「情報の届け方」の実証実験を行います。
① 「完璧なトリセツ」が直面する、検索画面の絶望
AIの日常活用が進む中、本連載ではこれまで、トリセツ情報を「必要な時に、必要な情報だけ、正確に伝える」ための手法を模索してきました。情報を意味のある単位に分割(チャンク化)し、「これは手順」「これは警告」といった厳密な名札(メタデータ)を付ける。これにより、社内のドキュメント管理システムや専用のサポートポータルの中では、どんな情報もピンポイントで呼び出せる「完璧な管理状態」ができあがりました。
しかし、現場のユーザーの視点や行動を想像してみてください。 機械が停止し、焦燥感に駆られながらユーザーが最初に頼るのは、分厚い紙の冊子でも、IDとパスワードが必要な専用ポータルでもなく、手元のスマートフォンにある「検索窓(Google)」ではないでしょうか。
「〇〇(製品名) フィルター交換」
油まみれの手で、そう検索したとき、私たちが苦労して構造化した情報は、意図した通りに表示されているでしょうか? 多くの場合、画面に現れるのは 「PDFファイルのダウンロードリンク」 だけです。ユーザーは、現場の不安定な電波の中で重たいファイルをダウンロードし、小さな画面で何十ページもスクロールし、小さな文字の海から自力で目的のページを探し出さなければなりません。情報の「中身」は完璧に整理されているのに、検索エンジンの前では、その価値がほとんど伝わっていないのです。
② 「配送伝票」と「地図」の壁
なぜ、このようなギャップが生まれるのでしょうか。それは、トリセツ管理で使っている「言葉」と、インターネットの世界で使われている「言葉」が根本的に違うからです。
前回までの記事で、私たちは国際規格(iiRDS/IEC PAS 63485)に基づいて情報を整理しました。これは、特定の相手に、特定の情報を確実に届けるための 「配送伝票(Delivery)」 としては完璧に機能します。一方で、インターネットの検索エンジンは、料理のレシピから最新ニュースまで、あらゆる情報を扱うために、もっと汎用的でシンプルな共通語を使っています。これが「Schema.org」と呼ばれるWeb標準の語彙であり、世界中の人々が情報を見つけるための 「地図(Discovery)」 の役割を果たしています。
私たちが作った詳細すぎる「配送伝票」は、あまりに専門的で厳密すぎたために、検索エンジンという、誰もが使う「地図」には載せてもらえなかったのです。
③ AIを「変換エンジン」として使う
では、検索で見つけてもらうためには、これまでの厳密な管理を捨てて、最初からWeb向けの曖昧な書き方をすべきなのでしょうか? 答えは 「No」 です。正確で詳細な情報(Delivery)があるからこそ、それを安全に要約し、広く伝える情報(Discovery)へと構造を変換することができます。逆は不可能です。そして今、この「専門家の言葉」を「Webの言葉」に瞬時に再構成してくれる強力なツールが存在します。それが 「生成AI」 です。
本記事では、シリーズ最終回として、以下の3つのステップで、トリセツ情報の「ラストワンマイル」をつなぐ方法を紐解いていきます。
- 変換のレシピ: 私たちが作った「詳細な手順データ」を、AIへの簡単な指示(プロンプト)だけで、Googleが好む「ハウツー形式」に変換する仕組みを解説します。
- 劇的ビフォーアフター: 変換されたデータがWebの世界に放たれると、検索結果の景色はどう変わるのか。「PDFリンク」との決定的な違いを、実際の画面イメージで比較します。
- テクニカルライターの新たな使命: 「書く」だけでなく「届ける」までをデザインする。AI時代におけるテクニカルライターの新しい役割について考えます。
プログラミングレスで、これらが実現できるのか。「閉じた正解」から、「開かれた解決策」へ。これまで積み上げてきたトリセツという資産を、情報のラストワンマイルまで届けるための最後の挑戦を始めます。
【これまでの記事】
AI時代のトリセツ設計:製品利用者に正確な情報を届けるために
1.AIは「文脈」の罠を乗り越えられるか?(前々回)
2.AIは情報の「意味」を理解できるか?(前回)
3.AIはトリセツの価値を「正しく」世界に届けられるか?(この記事)
【補足情報】
▼検証資料について 本記事の検証に使用した生成AIで読み込んだ入力資料など、資料編ページに掲載しております。ご自身で実際に試される際にご活用ください。(資料編ページはこちらへ)
▼使用した生成AIについて 検証にはGoogle Geminiを使用しています。(Geminiのページはこちらへ)
【検証】 スマート・ポンプの「フィルター交換手順」で実験
今回、検証の題材に使うのは、架空の産業用ポンプ「スマート・ポンプ SP-Xシリーズ」のトリセツ(User Manual)です。(実験用にAIを用いて作成しました。)
前回(12月号)は、シンプルに説明できるよう、「PCのメモリやCPUの交換手順」を例に、情報のバラバラ化(チャンク化)を試しました。今回は、「国際規格(iiRDS)からWeb標準(Schema.org)への変換」 を検証するために、よりリアルな状況に近づけるよう、複雑な分岐を持つ 『産業用スマートポンプ』 を実験台にします。
機種によって異なる手順、特定のモデルにしか存在しない致命的な危険(化学熱傷など)。 これら「ヒトでも読み間違えそうな情報」を、AIはどう処理し、どう最適化するのか。 PCパーツの時よりもさらに一歩踏み込んだ実践的な検証を進めます。
① 元のマニュアル:情報の「塊(かたまり)」
元となるデータは、ポンプの「第3章 フィルターエレメントの交換」です。
- 対象ドキュメント: スマート・ポンプ SP-Xシリーズ 取扱説明書
- 特徴: 共通の手順の中に、「標準モデル(SP-X100)」と「耐薬品モデル(SP-X200)」の異なる指示が混在しています。
- 課題: PDFのままでは、ユーザーは自分に関係のない「予備知識」や「他機種の警告」まで全て読み解かなければ、正解にたどり着けません。
<詳細>
資料1:スマート・ポンプ SP-Xシリーズ取扱説明書
② iiRDS化:プロが仕立てた「情報のカード」
まず、このマニュアルをAIを使って「意味のある単位」に切り分け、専門的な名札(iiRDS)を付けました。これが「Delivery(配送)」のための準備です。
AI対応トリセツの構造(抜粋)
- カードA 【メンテナンスの概要】 (種類:概念 / 全機種共通)
- カードB 【安全上のご注意:化学熱傷】 (種類:安全 / SP-X200専用)
- カードC 【旧フィルターの除去】 (種類:手順 / SP-X100専用)
- カードD 【旧フィルターの除去】 (種類:手順 / SP-X200専用)
このように細かく分解され、名札(メタデータ)がついたことで、システムは「今、SP-X100を使っている人には、カードCとAだけを見せる」という正確な配送(Delivery) ができるようになりました。しかし、これはまだ「専門家のシステム」の中だけの話です。
<詳細>
資料2:AI対応トリセツを作成するためのプロンプト
資料3:iiRDSメタ情報を付与したAI対応トリセツ
③ Schema.org化:「Webの共通語」への構造変換
ここからが今回の本題です。
プロ向けに整理された「iiRDSデータ」を、一般の検索エンジン(Googleなど)が理解できる「Schema.org」形式へ、AIを使って変換します。この作業を、システム用語では「マッピング」と呼びますが、要するに「情報の変換ルール」を決める作業です。トリセツの中で「手順(Task)」と呼んでいたものを、Webの世界では「ハウツー(HowTo)」と呼び変えよう、というルール作りです。
1)情報変換ルールの定義(マッピング)
AIに指示を出す前に、「情報の意味」をどう繋ぐか、設計図を描きます。
| プロの世界 (iiRDS) | 変換のルール (Logic) | Webの世界 (Schema.org) |
|---|---|---|
| Topic Title (見出し) | → ユーザーが検索する言葉へ → | HowTo / name |
| GenericTask (手順) | → 順序のあるステップへ変換 → | HowToStep |
| GenericReference (工具) | → 必要な道具リストへ変換 → | HowToTool |
| ProductVariant (機種) | → その機種以外の情報を除外 → | (フィルタリング) |
| Safety (安全情報) | → 手順の直前に「警告」として挿入 → | Step / text |
ポイントは、単純な項目の置き換えだけでなく、「機種情報のフィルタリング」や「安全情報の埋め込み」といった 編集的なロジック を組み込んでいる点です。
2)AIへの「編集指示」を出す(プロンプト)
方針が決まれば、あとはAIに指示(プロンプト)を出します。 ここで重要なのは、プログラムコードを書くのではなく、「有能な編集アシスタントへの指示書」 を渡す感覚で依頼することです。
▼ AIへの指示内容(要約)
ここに、iiRDS形式で整理されたマニュアルデータがあります。これを以下のルールで、Google検索用の「Schema.org (JSON-LD)」に書き換えてください。
- 構造化: 手順データは、Webの「HowTo(ハウツー)」形式に構成し直すこと。
- 選別(重要): 「SP-X100」と「SP-X200」、それぞれの機種専用のファイルを作成すること。その機種に関係のない情報は一切含めないこと。
- 安全確保: 警告情報は省略せず、作業ステップの冒頭に【警告】として目立つように配置すること。
ここで「どのように変換するか(How)」をコードで書く必要はありません。「どうあってほしいか(What)」という 理想の状態(Intent) を伝えるだけで、AIはiiRDSという正確な原稿を読み解き、一瞬でWeb検索に最適化されたコードを生成します。
<詳細>
資料4:Webの共通語への構造変換するためのプロンプト
資料5:Webの共通語への構造変換した結果
【検索結果の進化】劇的ビフォーアフター:検索画面の景色を変える
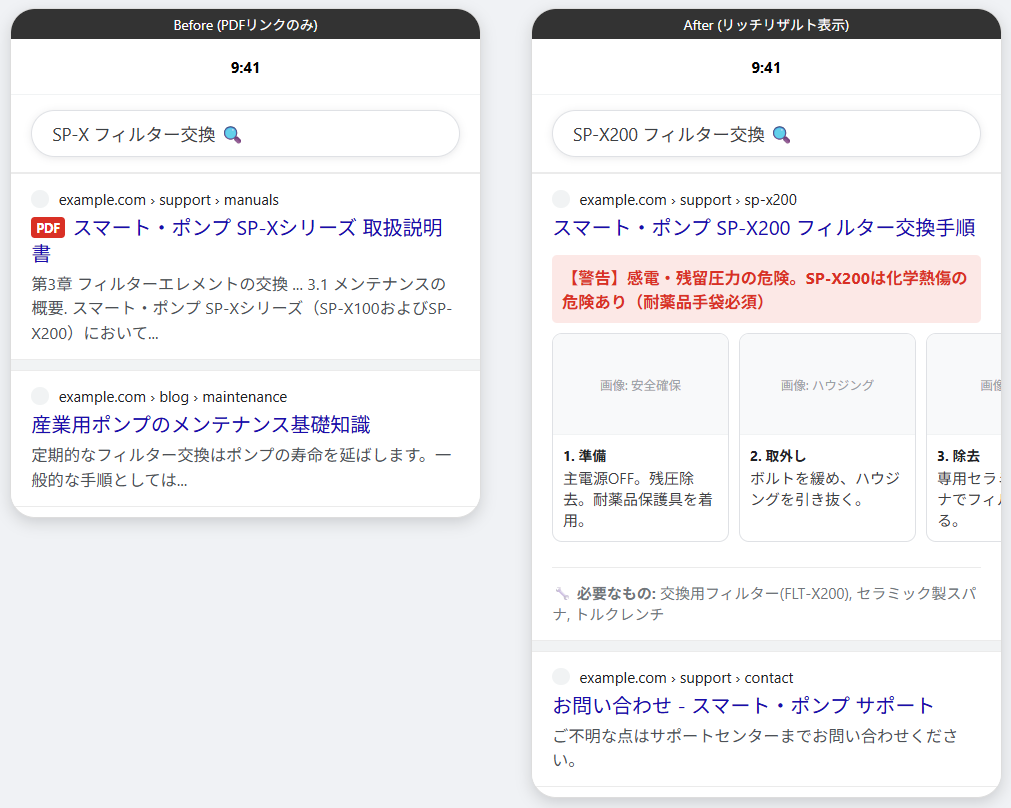
AIによる「変換」の結果、「スマート・ポンプ(SP-Xシリーズ)」のデータは、Googleの検索画面でどのように進化したのでしょうか。 百聞は一見にしかず。まずは、ユーザーが見ることになる実際のスマートフォンの画面を比べてみてください。
この「景色の違い」がもたらす決定的な変化を、3つのポイントで解説します。
① 発見の形:PDFリンクから「答え」へ
Before(従来の検索結果):
Googleで「SP-X フィルター交換」と検索して表示されるのは、「SP-Xシリーズ 取扱説明書.pdf」 へのリンクのみでした。ユーザーは、現場で重たいPDFをダウンロードし、小さな画面で「第3章」を探し出すまで、答えにたどり着けませんでした。
After(今回の実験結果):
検索画面に、AIが書き出した 「リッチリザルト(手順のカード)」 が直接出現します。画面上に「1. 準備」「2. ハウジングを外す」という具体的なステップが、Webサイトを訪れる(クリックする)前にリストアップされます。これは、情報を探す時間をゼロにしたことを意味します。
② 安全の形:埋もれていた「警告」が最前線へ
Before(従来の検索結果):
「残留圧力」や「化学熱傷」といった重大な警告は、マニュアルの本文中に埋もれていました。ユーザーがそこまで読み進めなければ、リスクは伝わりません。
After(今回の実験結果):
今回の変換ロジックにより、検索結果の最初のステップに 「【警告】感電の危険/化学熱傷の危険(SP-X200のみ)」 という警告が自動的に挿入されました。 ユーザーがスマホを取り出し、作業を開始しようとした「その瞬間」に、最も重要なリスクを伝えることができます。これは「Discovery(発見)」の段階で事故を防ぐ、新しい安全設計の形です。
③ 適合の形:自分に関係ない情報が消える
今回の最大の成果:
iiRDSで付与していた「対象機種(SP-X100/X200)」のメタデータが、Schema.orgへと見事に引き継がれました。
SP-X100(標準)で検索した人:
セラミック製スパナの使用指示は表示されません。
SP-X200(耐薬品)で検索した人:
薬液への警告と、専用スパナの準備が正しく表示されます。 情報の精度を落とすことなく、その人にとっての「正解」だけを届けることができました。ユーザーはもう、「※但し、耐薬品モデルを除く」といった注釈に惑わされることはありません。
【考察】 AIは何を行ったのか
実験の結果、iiRDSからSchema.orgへの変換は成功しました。しかし、ここで注目すべきは、AIが単なる「ファイル形式の変換(JSONからJSON-LDへ)」を行っただけではないという点です。AIは、提供した構造化データを読み解き、Webという文脈に合わせて情報を 「再構成(リストラクチャ)」 しました。
なぜ最初からSchema.orgで書かないのか?
読者の皆さんは、こんな疑問を持たれたかもしれません。「Webで見つけやすくしたいなら、最初からSchema.orgの形式でマニュアルを書けばいいのでは? なぜわざわざiiRDSを経由するのか?」と。
ここに、今回の実験の最大の示唆があります。 AIがここまで的確に情報を処理できたのは、元のデータ(iiRDS) が 「高解像度」 に構造化されていたからです。
- iiRDS(プロの世界): 厳密に定義された「正解」のデータベース。あらゆる条件分岐や詳細が含まれる「原文」。
- Schema.org(Webの世界): ユーザーに分かりやすく要約された「案内」のインターフェース。検索意図に合わせた「抄訳」。
もし最初から「Web用の簡易な書き方」をしてしまうと、詳細な技術情報や厳密な条件分岐が失われてしまいます。「高解像度な正解(Source)」があるからこそ、AIは自信を持って、安全性を損なうことなく「低解像度な案内(Service)」を生成できるのです。
これは、AIに学習データではなく、外部の事実データのみを参照させて回答させる「グラウンディング(Grounding)」と呼ばれる手法であり、技術的にもハルシネーション(嘘の生成)を抑制する理にかなったアプローチです。この 「原文(Asset)と要約(Service)の主従関係」 こそが、ハルシネーション(嘘の生成)を防ぎ、企業が安心してAIを活用するための鍵となります。
仕事が変わるのではなく、スキルが「拡張」する
このプロセスを実現するために、私たちが新しくプログラミングを学んだり、複雑なエンジニアリングを習得したりする必要はあるのでしょうか? 答えは 「No」 です。今回の実験で私は、コードを一行も書いていません。それどころか、AIへの指示出し(プロンプト)さえも、日本語で「こうしたい」と伝えただけです。 これは、今後この取り組みを進める上で非常に勇気づけられる事実です。
- 今のスキルがそのまま使える:
「誰に、何を、どう伝えたいか」という企画・構成力さえあれば、あとは優秀なアシスタント(AI)が、それをWebやシステムの言葉に変換してくれます。 - 作成から「届ける」まで:
これまでは「作って終わり」だったかもしれない仕事が、AIというツールを活用することで、「ユーザーの手元に届ける」ところまで、労力をかけずに拡張できるのです。
AIは、私たちの仕事を奪ったり、無理やり変化させたりするものではありません。 面倒な変換作業をすべて引き受け、私たちが積み上げてきた専門知識(コンテンツ)を、これまで届かなかった場所へ運んでくれる 「強力な増幅器」 なのです。
今回は検証のためにチャット画面で対話を行いましたが、実運用ではこの「変換ルール(プロンプト)」をシステム(API)に組み込むことで、マニュアル改訂と同時にWeb側のデータも全自動で更新する仕組みを作ることも可能です。
【結び】 トリセツの未来図:「静かな資産」から「動く解決策」へ
本連載の旅路の終着点で見えてきたのは、テクニカルライティングの新しい可能性です。これまでのマニュアル制作において、「納品」は一つの大きなマイルストーンでした。しかし、その先にある「ユーザーが検索画面でどう情報に出会うか」までは、物理的な制約もあり、私たちの手の届かない領域(スコープ外)としてきました。けれど本来、「どんなトラブルの時に、どの情報が必要なのか」を最も熟知しているのは、トリセツ(User Manual)を作り上げた私たちテクニカルライター自身のはずです。
今回の実験で、メタデータを付与したり、Web向けに再構成したりといった「膨大な手間」は、AIというツールが対応できることが実証されました。 私たちが持つ「構成力(構造化)」をAIというエンジンに注ぎ込むことで、情報は必要なときに、必要な場所で、必要な形に姿を変えてユーザーを助ける 「生きた解決策(Service)」 へと進化するのです。
管理と発見の統合
iiRDSで情報を守り(管理)、Schema.orgで情報を開く(発見)。
相反するように見えるこの二つの軸を、AIがつなぎ合わせました。「正確さ」を犠牲にすることなく、「見つけやすさ」を手に入れる。この両立こそが、AI時代のトリセツのあるべき姿です。
ラストワンマイルを越えて
「閉じた正解」から、「開かれた解決策」へ。
皆さんの手元にあるその専門知識は、構造化という羽を得ることで、世界中のユーザーを助ける力へと変わります。AI時代のトリセツは、もう、誰にも見つけられない棚の奥で眠ることはありません。必要なときに、必要な人の手の中で、解決の光を放ち続けるのです。
<コラム> AIの「燃費」を良くする情報設計 ~Green AIへの貢献~
1. 物理の省エネ、論理の省エネ 本記事では、情報を「見つけやすくする(Discovery)」ための構造化について解説してきましたが、この取り組みには、ユーザビリティの向上以上に、今の時代だからこそ語るべきもう一つの重大な価値があります。それは、「AIのエネルギー効率(Green AI)」への貢献です。生成AIの普及に伴い、データセンターの消費電力増大は世界的な課題です。冷却効率の改善やハードウェアの進化といった「物理的な省エネ」が叫ばれていますが、その上で動く 「データの中身(論理)」 の効率化は見落とされがちです。
2. 非構造化データは「燃費」が悪い PDFのマニュアルをそのままAIに読み込ませる(RAG)ケースを想像してください。AIは、文章をバラバラの断片(チャンク)として扱いますが、そこに「これは警告」「これは仕様」といった 「情報の名札(メタデータ)」 がなければ、AIは質問と関係のない膨大なテキストまで総当たりで計算処理することになります。これは、図書館で目録を使わずに、本棚の端から端まで本を開いて探すようなもので、GPUというエンジンを激しく「空ふかし」させます。一方で、今回実践したような「構造化データ」はどうでしょうか。断片化された情報に「これはトラブルシューティング」というタグが付与されているだけで、AIは 計算対象を瞬時に絞り込むことができます。情報の正確性が上がるだけでなく、計算量が物理的に減るため、劇的な省エネにつながるのです。
3. テクニカルライターの新しい貢献 「マニュアルを作る」という私たちの仕事は、これまでは「ユーザーの時間を節約する」ことでした。しかしこれからは、「AIの計算資源(電力)を節約する」 ことにも直結します。 ノイズを減らし、一発で正解を届けること。情報の構造化は、企業のDX成功だけでなく、持続可能なAI社会(Sustainable AI) を実現するための、私たち情報アーキテクトができる「静かですが、確実な環境活動」なのです。
【お知らせ】 連載タイトルのリニューアルについて
最後に、読者の皆様へ大切なお知らせがあります。 本連載はこれまで、「執筆時のAI活用で翻訳しやすい日本語をつくる」 というタイトルのもと、主に「翻訳(Translation)」を起点とした品質向上の手法を探求してきました。しかし、ここ数回の実験を通して私たちが目撃したのは、AIの活用範囲が「言語の変換」という枠組みを大きく超えようとしている姿でした。 情報を構造化し、必要な人に、必要な形で届ける。それは単なる翻訳作業ではなく、トリセツという資産を使って「新しい価値」を設計するプロセスそのものです。
そこで、この変化に合わせて、来月(2026年2月号)より連載タイトルを以下のようにリニューアルいたします。
【新タイトル】
執筆時のAI活用で「価値あるトリセツ」を届ける
~AI時代の情報設計~
「翻訳しやすさ」はもちろん重要な要素として残りますが、これからは視座を一段上げ、「AIを活用して、いかにユーザーにとって価値ある情報体験(情報設計)を作り出すか」 というテーマで、より実践的で幅広い話題をお届けします。
次号からの展開:理想から「現実」へ
リニューアル第1弾となる次回からは、今回描いた未来図を、皆さんの現場(現実)に着地させるための具体的な課題に向き合います。
- 「今ある山のようなPDF資産をどうするのか?」
- 「人間の『暗黙知』はAIに継承できるのか?」
- 「セキュリティの壁や、AIの嘘(ハルシネーション)とどう戦うか?」
綺麗事だけでは終わらせない、現場の泥臭い課題をAIと共に乗り越えていく「価値あるトリセツ」への挑戦。 新しいタイトルと共に、来月もまたお会いしましょう。
<付録1> iiRDSからSchema.orgへの変換ルール:逆引きリファレンス
本記事で紹介した変換ロジックの実装ガイドです。社内の構造化ガイドラインに追加するなどしてご活用ください。
1. 基本マッピング定義表
iiRDSの各要素を、Schema.orgの HowTo 構造へどのように「再構成」するかの定義です。
| 実現したいWeb表示 (Schema.org) | 対応するiiRDS要素 (Source) | 変換時の処理・ロジック |
|---|---|---|
ハウツーの名称 (name) | Title (トピック全体) | ユーザーの検索意図(キーワード)に合わせて調整。 |
全体の概要 (description) | iirds:GenericConcept | 「概要」や「目的」を要約して流し込む。 |
個別ステップ (step) | iirds:GenericTask | 独立したカードを、順序性を持ったリストに再構成。 |
ステップの見出し (name) | Title (各Task内) | 検索結果で太字表示される短いアクションを抽出。 |
ステップの説明 (text) | Content (各Task内) | 詳細説明から不要な文言を削り、簡潔にする。 |
必要な工具 (tool) | iirds:GenericReference | 品目名、規格、型番を HowToTool としてリスト化。 |
| 安全警告 (警告文の挿入) | iirds:GenericSafety | 【重要】 最も関連するステップの text 冒頭に統合。 |
| 機種の絞り込み | ProductVariant | 機種タグに基づき、無関係な情報を変換対象から除外。 |
2. 実装のTips
- 警告情報の挿入位置:
Schema.orgには独立した「安全セクション」がありません。Googleのリッチリザルトでは、手順(Step)のテキスト冒頭に【警告】を入れるのが最も視認性が高く、推奨されるベストプラクティスです。 - JSON-LDの検証:
AIが生成したコードは、必ずGoogle公式の「リッチリザルト テスト」にかけてください。構文エラーだけでなく、「必須プロパティの欠落」もチェックできます。
<付録2> SEOからGEOへ:AIに選ばれるための布石
本記事では、検索エンジン(Google)対策としての「SEO」の視点で解説しましたが、今回行った「Schema.orgへの構造化」には、もう一つの、そしてより未来に向けた重要な意味があります。それは、GEO(Generative Engine Optimization:生成AI検索エンジン最適化) への対策です。
AIは「構造化されたデータ」を好む
ChatGPTやPerplexity、GoogleのAI検索(AI Overview)などの生成AIは、回答を生成する際、信頼できる情報源を探しに行きます。このとき、AIにとって「単なるテキストの羅列(PDFや非構造化HTML)」は、文脈を読み違えるリスクがあるデータです。
一方で、今回作成したSchema.org(JSON-LD)は、「これは手順です」「これは警告です」と機械的に定義されたデータです。 AIにとってこれほど「理解しやすく、引用しやすい」形式はありません。
「正解データ」としての地位を確立する
今後、ユーザーは検索窓にキーワードを入れるのではなく、AIチャットに「SP-Xのフィルター交換方法を教えて」と話しかけるようになります。 その時、あなたのマニュアルが構造化されていれば、AIはそれを「信頼できる正解(Source of Truth)」として認識し、回答のベースとして採用する確率が格段に高まります。
今回の実験は、今の検索(SEO)を改善するだけでなく、来たるべきAI検索時代(GEO)において、自社の情報を「その他大勢」から「選ばれる正解」へと押し上げるための、最初にして最大の投資なのです。
<付録3> トリセツにはどれを使う? Schema.org タイプ選定ガイド
トリセツ(User Manual)やヘルプサイトを構造化する際、「どのSchemaタイプ(型)を使えばいいのか?」 で迷うことはありませんか?
今回の実験で採用した HowTo 以外にも、ドキュメントの性格によって最適なタイプは異なります。Google検索での表示のされ方(リッチリザルト)の違いから、最適なタイプを選ぶためのクイックガイドをまとめました。
1. タイプ別・選定早見表
情報の「中身」に合わせて、以下の4つから最適なものを選んでください。
| トリセツの記載内容 | オススメの Schema タイプ | Google検索での見え方・メリット |
|---|---|---|
| 手順書・操作マニュアル | HowTo (今回採用) | 手順のステップ(1.〜 2.〜)が検索結果に直接表示される。画像付きも可。ユーザーが「やり方」を知りたい場合に最強の視認性を誇る。 |
| トラブルシューティング | FAQPage | Q&A形式のアコーディオンが表示される。「〜できない時は?」「エラーコードE01とは?」といった逆引きコンテンツに最適。 |
| 技術仕様・製品概要 | TechArticle | 派手なリッチリザルトは出にくいが、AI(SGE)が技術情報を引用する際のソースとして信頼性が高まる。「記事」として認識させる基本形。 |
| 用語集 | DefinedTermSet | 用語とその定義のペア。強調スニペット(用語の解説枠)に採用されやすくなる。専門用語の多いマニュアルにおすすめ。 |
2. SEO/GEOのための実装Tips
- まずは「HowTo」と「FAQPage」から:
クリック率(CTR)へのインパクトが最も大きいのは、検索結果の面積を大きく占有できるこの2つです。まずはここから実装を始めるのが、費用対効果の高い戦略です。 - JSON-LDは「分離」して管理する:
HTMLの中に直接埋め込むこともできますが、管理のしやすさを考えると、
<script type="application/ld+json">として、データブロックとして分離することをお勧めします。これにより、CMSなどでの自動生成が容易になります。
- 必須プロパティをGoogleで確認:
Schema.orgの公式仕様には多くのプロパティがありますが、Googleがリッチリザルトを表示するために「必須」としているプロパティは限られています(例:HowToなら step が必須)。実装前には必ず Google 検索セントラル のドキュメントを確認してください。
<終わりーAI時代のトリセツ設計:「正確に作ったはずのトリセツ」が、なぜ検索で見つからないのか?>







